
This guide will show you what a CAPTCHA is, explain each CAPTCHA type, tell you common triggers, and explains different ways to bypass them.
HTTP Proxies are handling HTTP requests towards the internet on behalf of a client. They are fast and very popular when it comes to any kind of anonymous web browsing.
SOCKSv5 is an internet protocol that is more versatile than a regular HTTP proxy since it can run on any port and traffic can flow both on TCP and UDP. Useful in games and other applications that do not use the http protocol.
Your data bot is gliding through a store site when a puzzle of traffic-light images pops up and everything stops. That puzzle is CAPTCHA, short for Completely Automated Public Turing Test to Tell Computers and Humans Apart. In 2025 these tests study mouse paths, keyboard rhythm, and tiny clues from your device to figure out if you are a program.
Sites use them to guard their content and keep fake traffic away, but for people who need steady data these pop-ups can feel like slammed doors. In this article we will see what CAPTCHAs are, the main kinds you meet online today, and clear ways to slip past each one so your scraper can keep working.
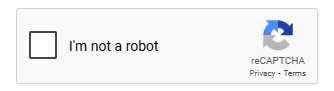
CAPTCHA is a short, catchy way of saying “Completely Automated Public Turing test to tell Computers and Humans Apart.” In plain English, it’s a quick quiz that sites give visitors to make sure a real person—not a script or bot—is knocking at the door. You’ve seen the usual suspects: warped letters to re-type, photo grids begging you to click every crosswalk, or a simple “I’m not a robot” checkbox. All of them share one goal: weed out automated traffic that can spam forms, flood log-ins, or suck up data at scale.
Most sites don’t roll out a CAPTCHA right away. They watch how you browse first. If the system spots red flags, say, dozens of page hits in seconds, or an IP address that bounces all over the globe, it flips the switch and serves a challenge. From there, a three-step routine kicks in:
The page displays a grid of street photos divided into equal squares. Your task is to click only the sections that show the requested object. Each click trains large computer vision datasets while confirming that real eyes, not an automated script, are making the choice. This format is everywhere, from checkout forms to blog comments, because it turns a simple human action into a strong filter for bots.

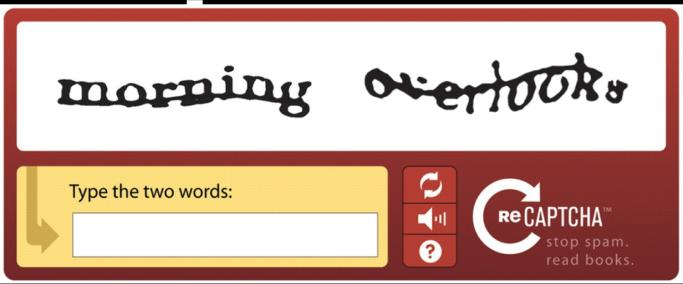
Random letters and numbers appear twisted, stretched, or overlapped by lines. A person can still read and retype them, but many optical character recognition tools stumble on the visual noise. Small forums and older registration pages often rely on this veteran style even though larger sites have moved to more advanced checks.

When someone clicks the speaker icon, a short recording plays. It usually contains words or digits buried under background hiss. The visitor enters what they hear, proving that human hearing, rather than a speech to text routine, picked up the message. This option keeps the site accessible to people with visual impairments while staying tough for automated attacks.
A tiny jigsaw piece appears beside a matching gap in a background photo. Users drag the piece until it locks into place. The system watches cursor speed, acceleration, and small pauses to judge whether a natural hand completed the motion. That behavioral data creates a solid barrier against simple scripted moves that mimic straight line drags at constant speed.

No checkbox, no puzzle, nothing obvious. As the page loads, a script quietly tracks mouse drift, scroll depth, keystroke rhythm, and even the time you keep the tab active. When the signals look normal, the visit proceeds without interruption. If something feels automated, the page instantly adds one of the visible challenges above. Critics say this approach can cross the line into aggressive fingerprinting, yet its seamless experience keeps winning converts.
A CAPTCHA system doesn’t wait for you to click before it judges you because it quietly tracks every signal your scraper sends. When those signals drift too far from normal human behavior, the site can slap you with a puzzle or serve blank pages. Here are five common trip-wires:
Trigger one or more of these signals and you are almost guaranteed to face a CAPTCHA, or worse, a silent block that returns empty data. The good news: every one of these barriers can be bypassed. Below we’ll show you exactly how.
The quickest way to look human is to spread your traffic across many household-grade addresses. When every request comes from a fresh, real-world connection, rate-limit counters stay low and CAPTCHA triggers rarely fire.
The proxy addresses shown below are only examples pulled from the Anonymous-Proxies dashboard when this guide was written; they will not work for you. Copy your residential IPs from your own dashboard and replace the placeholders, along with your personal username and password, before running the script. If you have already whitelisted your device’s IP, you can delete the username and password fields entirely.
import itertoolsimport requests# Change to your username and password from the dashboardUSER = "YOUR_PROXY_USER"PASS = "YOUR_PROXY_PASS"# Put your residential endpoints you want to testPROXY_POOL = [{"ip": "46.151.227.8", "port": "43233"},{"ip": "185.174.158.21", "port": "61749"},{"ip": "77.83.249.104", "port": "50926"},{"ip": "91.113.248.115", "port": "57721"},]# Endless cycler over the poolproxy_cycle = itertools.cycle(PROXY_POOL)# Rotate your proxiesfor i in range(3):p = next(proxy_cycle)proxy_cfg = {"http": f"http://{USER}:{PASS}@{p['ip']}:{p['port']}","https": f"http://{USER}:{PASS}@{p['ip']}:{p['port']}",}try:r = requests.get("https://httpbin.io/ip", proxies=proxy_cfg, timeout=10)print(f"Request {i+1}: origin → {r.json()['origin']}")except requests.exceptions.RequestException as err:print(f"Request {i+1}: connection failed → {err}")
{"origin": "45.43.133.61"}{"origin": "185.174.158.21"}{"origin": "77.83.249.104"}
Search-engine crawlers, rate-limit monitors, and CAPTCHA traps all look for the one thing real people rarely do, and this is perfect repetition. To slip past these filters, make every move feel organic:
The easiest way to layer in all those signals is to drive your scraper with a headless browser. Tools like Puppeteer render full JavaScript, load fonts, and expose a fresh, believable fingerprint for each session. You can check this Puppeteer integration tutorial for more details.
Some sites refuse to show real content unless they detect a full browser environment. A headless browser passes that test by loading every script, font and canvas call the page expects. Playwright is a natural first choice because it hides most automation fingerprints while letting you script believable actions such as small mouse nudges, gentle scrolls and momentary pauses. You can see how to connect Playwright to your residential proxies in this Playwright integration tutorial.
If your project already relies on WebDriver, Selenium paired with the Selenium Stealth plug-in offers the same camouflage. It masks tell-tale headless clues and tweaks browser fingerprints so detection scripts accept your session as genuine. Full setup instructions are in this Selenium integration tutorial.
So, if you render every page the way a normal visitor would and add a few human touches, most CAPTCHA barriers will quietly step aside.
A CAPTCHA resolver is a safety net for the rare moments your other defenses do not work. Think of it as an outsourced brain that handles the puzzle for you. The flow is simple.
Challenge appears. Your scraper meets a puzzle it can’t dodge.
Data captured. The script grabs the image, token, or site-key that defines the test.
Ticket opened. That information goes to a service like 2Captcha or Anti-CAPTCHA through their API.
Human solve. A real person on the service’s side cracks the puzzle and sends back the answer.
Door unlocked. Your scraper submits that answer and moves on as though nothing happened.
Because real humans are in the loop, these services can crack almost any puzzle from old distorted text to modern image grids and hCAPTCHA variants. The trade-off is cost and delay. Each solved challenge usually costs a few cents and the turnaround takes anywhere from several seconds to half a minute, so heavy use can eat into budgets and slow large-scale jobs. That is why a resolver should sit at the very end of your strategy, ready to step in only when rotating proxies, human-like timing, and headless browsing still leave you staring at a puzzle.
Now you’ve seen that CAPTCHAs are built to snare bots, not determined data explorers. If you follow the ways to bypass CAPTCHAs we talked about above, like rotating clean residential proxies, browsing at human speed, loading pages in a stealth browser and leaning on a CAPTCHA resolver only as a fallback, you should not have any problems in your scraping activities.
If you have any questions or encounter any proxy problems, feel free to contact our support team.
We offer highly secure, (Dedicated or Shared / Residential or Non-Residential) SOCKS5, Shadowsocks, DNS or HTTP Proxies.
DR SOFT S.R.L, Strada Lotrului, Comuna Branesti, Judet Ilfov, Romania
@2025 anonymous-proxies.net