
Web scraping can feel complex, from definitions to real business uses and future impact. And there is web crawling too. These terms are often mixed up. This guide will show you the differences between a web crawler and a web scraper and how are they used in the real world.
HTTP Proxies are handling HTTP requests towards the internet on behalf of a client. They are fast and very popular when it comes to any kind of anonymous web browsing.
Web scraping is automated data extraction from specific web pages that turns HTML or JSON into structured records ready for analytics, dashboards, and machine learning. A scraper sends requests to target URLs, reads the response, and captures fields such as titles, prices, SKUs, authors, dates, specs, and ratings so you end up with a clean dataset instead of a bundle of pages.
A good scraping workflow follows a simple path from target selection to delivery. We can start by picking the right places to pull data from, like category pages, search results, or official APIs, etc. Make requests politely with clear headers and a recognizable user agent. Then, we can continue to parse the pages and clean up the data: fix number and date formats, remove duplicates, and save everything to CSV, JSON, or your database. Finally, put it on a schedule that matches the business, hourly for prices, daily for listings.
Web crawling is like sending out little digital explorers, called crawlers or bots, that automatically travel across websites, scanning and collecting information from pages so it can be organized, stored, and later used, exactly how search engines build their giant libraries of the internet.
For a simple mental model, think of Googlebot. It discovers pages, fetches content, records status codes and response times, detects changes, and hands the results to indexing systems so search can show the right version of each page.
Keep in mind that: Crawling and scraping usually work together. Crawling keeps a clean, up-to-date list of relevant URLs. Scraping turns those pages into structured fields that power reports and applications.
The quick answer: crawling finds pages and tracks what changed, while scraping pulls specific fields from pages you already care about.
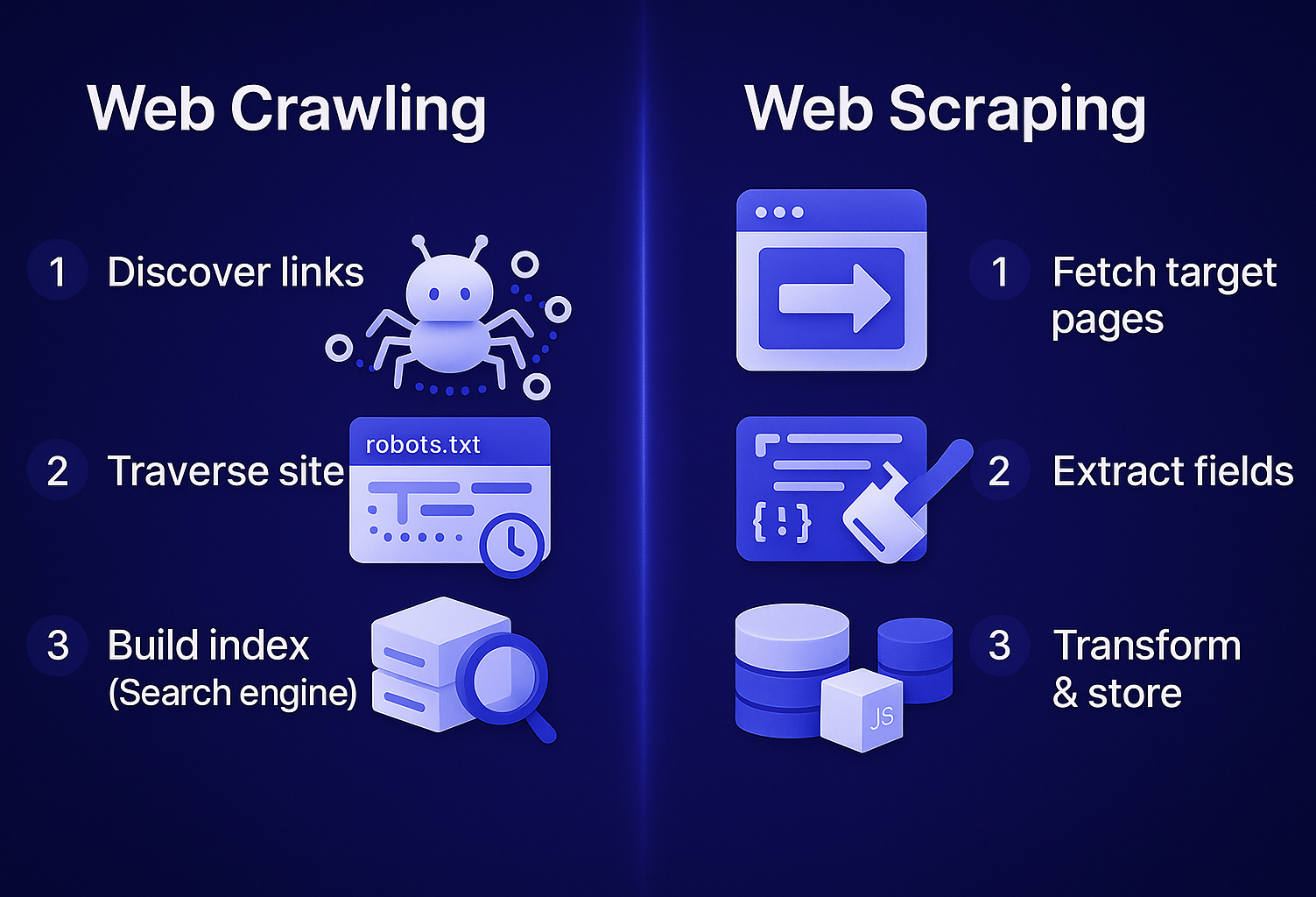
Crawling is the wide-angle lens: it roams the web to discover and keep track of what’s out there at scale. Scraping is the zoom lens: it returns to specific pages you care about and pulls the exact fields you need.
Web crawling is about discovery and coverage. Think of it as building and maintaining a living map of pages. You will reach for a crawler when you need to know what exists, what changed, and what to visit next. Its main use cases are next two:
Crawl your site or an entire set of domains to power internal search and navigation. Crawling keeps an index fresh so new articles, product pages, and documentation appear in search results without manual submissions.
Large content libraries drift every day. A crawler tracks new pages, removed pages, and significant edits. Feed these signals to alerts or workflows so editors, merchandisers, and product teams react quickly.
Web Scraping is about precision. You know what pages matter and you need exact fields captured on a schedule with quality checks.
Keep an eye on product pages to grab today’s price, last week’s price, promo banners, and stock status. Drop it into a simple dashboard so you can spot undercuts, match a sale, or move inventory before it sits.
Pull titles, specs, images, and reviews from many sources and tidy them up. “8GB” vs “8 GB” becomes one clean value, so your filters actually make sense and shoppers find what they want faster.
Collect headlines, authors, canonical links, and tags from publishers and blogs. Turn that into morning briefings, instant alerts, and competitive press trackers, so there's no need to copy-paste it by yourself.
Find basic, public company details like name, location, industry, and the official contact page, and add them to your CRM. Your reps get useful context without grabbing personal data you don’t have a clear right to use.
Pull listings into one view with neighborhood, amenities, fees, and dates. Line them up side-by-side so it’s obvious which place has parking, late checkout, or that sneaky cleaning fee.
Collect ratings and real review snippets, toss out spam and near-duplicates, then tag common themes like “battery life,” “fit,” or “customer support.” Hand teams a simple summary that points to what to fix next.
Keep an eye on marketplaces, social posts, and forums for your brand and product names. Catch lookalike pages or counterfeit listings early, and bundle the proof like links, screenshots, timestamps, so takedowns move quickly.
Web crawling maps what exists and what changed; web scraping turns those pages into clean, structured data your team can actually use. Together, they power price intelligence, healthy product catalogs, sharper research, and stronger brand protection.
If you want to run a scraper reliably at scale, you must opt for residential proxies since they can distribute requests across real ISP IPs, maintain sticky sessions, and reduce blocks so your data stays consistent.
If you have any question about setting a proxy with a web scraper or have any question related to proxies or VPNs in general, don't hesitate to contact our support team.
We offer highly secure, (Dedicated or Shared / Residential or Non-Residential) SOCKS5, Shadowsocks, DNS or HTTP Proxies.
DR SOFT S.R.L, Strada Lotrului, Comuna Branesti, Judet Ilfov, Romania
@2025 anonymous-proxies.net